Model reduction¶
Linear reduced-order models¶
We provide a class to find reduced-order models (continuous and discrete time) by projecting linear dynamics onto modes (Petrov-Galerkin projection). The governing equation of the full system is assumed to be either continuous time:
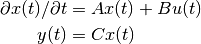
or discrete time:

where  is the time step.
Here
is the time step.
Here  is the state vector.
is the state vector.
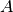 ,
, 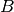 , and
, and 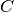 are, in general, linear operators (often
arrays).
In cases where there are no inputs and outputs, and are
zero.
acts on and returns a vector that lives in the same vector
space as .
acts on elements of the input space,
are, in general, linear operators (often
arrays).
In cases where there are no inputs and outputs, and are
zero.
acts on and returns a vector that lives in the same vector
space as .
acts on elements of the input space, 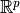 , where
, where  is
the number of inputs and returns elements of the vector space in which
lives.
acts on and returns elements of the output space,
is
the number of inputs and returns elements of the vector space in which
lives.
acts on and returns elements of the output space,
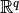 , where
, where  is the number of outputs.
is the number of outputs.
These dynamical equations can be projected onto a set of modes.
First, approximate the state vector as a linear combination of  modes,
stacked as columns of array
modes,
stacked as columns of array 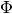 , and time-varying coefficients
, and time-varying coefficients
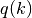 :
:
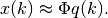
Then substitute into the governing equations and take the inner product with a
set of adjoint modes, columns of array  .
The result is a reduced system for , which has as many elements as
has columns, .
The adjoint,
.
The result is a reduced system for , which has as many elements as
has columns, .
The adjoint,  , is defined with respect to inner product weight
, is defined with respect to inner product weight
 .
.
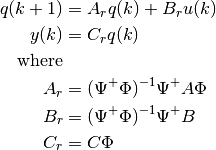
An analagous result exists for continuous time.
If the modes are not stacked into arrays, then the following equations are
used, where ![[\,\,]_{i,j}](_images/math/9015573ba3b7210b041c08dbdfbfa23072114b9c.png) denotes row
denotes row  and column
and column 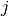 .
.
![[\Psi^+ \Phi]_{i,j} &= \langle\psi_i,\, \phi_j \rangle_W \\
[\Psi^+ A \Phi]_{i,j} &= \langle\psi_i,\, A \phi_j\rangle_W \\
[\Psi^+ B] &= \langle \psi_i,\, B e_j\rangle_W \\
[C \Phi]_{:,j} &= C \phi_j](_images/math/4e65feb11cdece9d0c1b2cafd97ddc2fd3a87630.png)
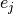 is the jth standard basis (intuitively
is the jth standard basis (intuitively 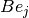 is
is
![[B]_{:,j}](_images/math/bff8496aa0bbf107a24dc6f6f34de8738f125aaf.png) if is an array.).
if is an array.).
The , , and operators may or may not be available
within Python.
For example, you may do simulations using code written in another language.
For this reason, modred requires only the action of the operators on the
vectors, i.e., the products  ,
,  , and
, and 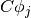 , and not the operators , , and themselves.
, and not the operators , , and themselves.
Example 1: Smaller data and arrays¶
Here’s an example that uses arrays.
import os
import numpy as np
import modred as mr
# Create directory for output files
out_dir = 'rom_ex1_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Create random LTI system
nx = 100
num_inputs = 2
num_outputs = 3
num_basis_vecs = 10
A = np.random.random((nx, nx))
B = np.random.random((nx, num_inputs))
C = np.random.random((num_outputs, nx))
# Create random modes
basis_vecs = np.random.random((nx, num_basis_vecs))
# Perform Galerkin projection and save data
LTI_proj = mr.LTIGalerkinProjectionArrays(basis_vecs)
A_reduced, B_reduced, C_reduced = LTI_proj.compute_model(
A.dot(basis_vecs), B, C.dot(basis_vecs))
LTI_proj.put_model(
'%s/A_reduced.txt' % out_dir, '%s/B_reduced.txt' % out_dir,
'%s/C_reduced.txt' % out_dir)
The array basis_vecs contains the vectors that define the basis onto which
the dynamics are projected.
A few variations of this are illustrative.
First, if no inputs or outputs exist, then there is only 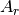 and no
and no
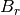 or
or 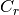 .
The last two lines would then be replaced with:
.
The last two lines would then be replaced with:
A_reduced = LTI_proj.reduce_A(A.dot(basis_vec_array))
LTI_proj.put_A_reduced('A_reduced.txt')
Another variant is if the basis vecs are known to be orthonormal, as is always
the case with POD modes.
Then, the 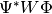 array and its inverse are identity, and
computing it is wasteful.
Specifying the constructor keyword argument
array and its inverse are identity, and
computing it is wasteful.
Specifying the constructor keyword argument is_basis_orthonormal=True tells
modred this array is identity and to not compute it.
Example 2: Larger data and vector handles¶
Here’s an example similar to what might arise when doing large simulations in another language or program.
import os
import numpy as np
from modred import parallel
import modred as mr
# Create directory for output files
out_dir = 'rom_ex2_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Create handles for modes
num_modes = 10
basis_vecs = [
mr.VecHandlePickle('%s/dir_mode_%02d.pkl' % (out_dir, i))
for i in mr.range(num_modes)]
adjoint_basis_vecs = [
mr.VecHandlePickle('%s/adj_mode_%02d.pkl' % (out_dir, i))
for i in mr.range(num_modes)]
# Define system dimensions and create handles for action on modes
num_inputs = 2
num_outputs = 4
A_on_basis_vecs = [
mr.VecHandlePickle('%s/A_on_dir_mode_%02d.pkl' % (out_dir, i))
for i in mr.range(num_modes)]
B_on_bases = [
mr.VecHandlePickle('%s/B_on_basis_%02d.pkl' % (out_dir, i))
for i in mr.range(num_inputs)]
C_on_basis_vecs = [
np.sin(np.linspace(0, 0.1 * i, num_outputs)) for i in mr.range(num_modes)]
# Create random modes and action on modes. Typically this data already exists
# and this section is unnecesary.
nx = 100
ny = 200
if parallel.is_rank_zero():
for handle in (
basis_vecs + adjoint_basis_vecs + A_on_basis_vecs + B_on_bases):
handle.put(np.random.random((nx, ny)))
parallel.barrier()
# Perform Galerkin projection and save data to disk
inner_product = np.vdot
LTI_proj = mr.LTIGalerkinProjectionHandles(
inner_product, basis_vecs, adjoint_basis_vec_handles=adjoint_basis_vecs)
A_reduced, B_reduced, C_reduced = LTI_proj.compute_model(
A_on_basis_vecs, B_on_bases, C_on_basis_vecs)
LTI_proj.put_model(
'%s/A_reduced.txt' % out_dir, '%s/B_reduced.txt' % out_dir,
'%s/C_reduced.txt' % out_dir)
This example works in parallel with no modifications.
If you do not have the time-derivatives of the direct modes but want a
continuous time model, see
ltigalerkinproj.compute_derivs_arrays() and
ltigalerkinproj.compute_derivs_handles().
Eigensystem Realization Algorithm (ERA)¶
See the documentation and examples provided in era.compute_ERA_model()
and era.ERA.