Modal decompositions – POD, BPOD, and DMD¶
This tutorial discusses computing modes from data, using the Proper Orthogonal Decomposition (POD), Balanced Proper Orthogonal Decomposition (BPOD), and Dynamic Mode Decomposition (DMD). For details of these algorithms, see [HLBR] for POD and BPOD and [TRLBK] for DMD.
The first step is to collect your data. We call each piece of data a “vector” or “vector object”. By vector, we don’t mean a 1D array. Rather, we mean an element of a vector space. This could be a 1D, 2D, or 3D array, or any other object that satisfies the properties of a vector space. The examples below build on one another, each introducing new aspects.
Example 1 – All data in an array¶
A simple way to find POD modes is:
import numpy as np
import modred as mr
# Create random data
num_vecs = 30
vecs = np.random.random((100, num_vecs))
# Compute POD
num_modes = 5
POD_res = mr.compute_POD_arrays_snaps_method(
vecs, list(mr.range(num_modes)))
modes = POD_res.modes
eigvals = POD_res.eigvals
Let’s walk through the important steps.
First, we create an array of random data.
Each column is a vector represented as a 1D array.
Then we call the function compute_POD_arrays_snaps_method, which returns
the first num_modes modes as columns of the array modes, and all of the
non-zero eigenvalues, sorted from largest to smallest.
This function implements the “method of snapshots”, as described in Section 3.4
of [HLBR].
In short, it computes the correlation array 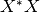 , where
, where 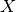 is
is
vecs, then finds its eigenvectors and eigenvalues, which are related to the
modes.
Example 2 – Inner products with all data in an array¶
You can use a weighted inner product, specified here by a 1D array of weights,
so that the correlation array is 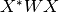 , where is
, where is vecs
and  contains the inner product weights.
The weights also can, more generally, be an array.
The vectors are again represented as columns of an array.
contains the inner product weights.
The weights also can, more generally, be an array.
The vectors are again represented as columns of an array.
import numpy as np
import modred as mr
# Create random data
num_vecs = 100
nx = 100
vecs = np.random.random((nx, num_vecs))
# Define non-uniform grid and corresponding inner product weights
x_grid = 1. - np.cos(np.linspace(0, np.pi, nx))
x_diff = np.diff(x_grid)
weights = 0.5 * np.append(np.append(
x_diff[0], x_diff[:-1] + x_diff[1:]), x_diff[-1])
# Compute POD
num_modes = 10
POD_res = mr.compute_POD_arrays_direct_method(
vecs, list(mr.range(num_modes)), inner_product_weights=weights)
modes = POD_res.modes
eigvals = POD_res.eigvals
This function computes the singular value decomposition (SVD) of 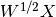 , and we refer to this as the “direct method” to distinguish it from the
method of snapshots in the previous example.
The differences between the two are insignificant in most cases.
For details, see
, and we refer to this as the “direct method” to distinguish it from the
method of snapshots in the previous example.
The differences between the two are insignificant in most cases.
For details, see pod.compute_POD_arrays_direct_method().
Example 3 – Vector handles for loading and saving¶
This example demonstrates vector handles, which are very important because they allow modred to interact with large and complicated datasets without requiring that all of the vectors be stacked into a single array. This is necessary, for example, if the data is too large to all fit in memory simultaneously.
The following example computes direct and adjoint modes using Balanced POD (see Chapter 5 of [HLBR]):
import os
import numpy as np
import modred as mr
# Create directory for output files
out_dir = 'tutorial_ex3_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Define handles for snapshots
num_vecs = 30
direct_snapshots = [
mr.VecHandleArrayText('%s/direct_vec%d.txt' % (out_dir, i))
for i in mr.range(num_vecs)]
adjoint_snapshots = [
mr.VecHandleArrayText('%s/adjoint_vec%d.txt' % (out_dir, i))
for i in mr.range(num_vecs)]
# Save random snapshot data in text files
x = np.linspace(0, np.pi, 200)
for i, snap in enumerate(direct_snapshots):
snap.put(np.sin(x * i))
for i, snap in enumerate(adjoint_snapshots):
snap.put(np.cos(0.5 * x * i))
# Calculate and save BPOD modes
my_BPOD = mr.BPODHandles(inner_product=np.vdot, max_vecs_per_node=10)
sing_vals, L_sing_vecs, R_sing_vecs = my_BPOD.compute_decomp(
direct_snapshots, adjoint_snapshots)
num_modes = 10
mode_nums = list(mr.range(num_modes))
direct_modes = [
mr.VecHandleArrayText('%s/direct_mode%d' % (out_dir, i))
for i in mode_nums]
adjoint_modes = [
mr.VecHandleArrayText('%s/adjoint_mode%d' % (out_dir, i))
for i in mode_nums]
my_BPOD.compute_direct_modes(mode_nums, direct_modes)
my_BPOD.compute_adjoint_modes(mode_nums, adjoint_modes)
First, we create lists direct_snapshots and adjoint_snapshots.
(“Snapshots” is just a common word to describe vectors that come from
time-sampling a system as it evolves.)
Each element in these lists is a vector handle (in particular, an instance of
VecHandleArrayText).
All vector handles have member functions to load, vec = vec_handle.get(),
and save, vec_handle.put(vec), but themselves use very little memory because
they do not internally contain a vector.
modred uses these vector handles to load and save individual vectors only as it
needs them.
All the snapshots are vectors and each is represented as an array, but they are
not stacked into a single 2D array.
Ordinarily the snapshots would already exist, for instance as files from a
simulation or experiment.
Here, we artificially generate snapshots and write them to file using the
put() method.
Next, we compute the BPOD modes.
The BPODHandles constructor takes an optional argument
max_vecs_per_node=10, specifying that only 10 vectors (snapshots + modes)
can be in one node’s memory at one time.
The function compute_decomp takes lists of vector handles as arguments.
In this example, note that there are 30 direct and 30 adjoint snapshots, so
handles are necessary to avoid violating max_vecs_per_node=10.
Similarly, compute_direct_modes and compute_adjoint_modes take lists of
handles.
The modes are saved via handle.put() rather than returned, which might
require too much memory.
Replacing VecHandleArrayText with VecHandlePickle would load/save all
vectors (snapshots and/or modes) to Python’s binary pickle files.
Note that pickling works with any type of vector, including user-defined ones,
whereas saving to text is only written for 1D and 2D arrays.
To run this example in parallel is easy.
The only complication is the data must be saved by only one processor, and
moving these lines inside an if block solves this:
parallel = mr.parallel_default_instance
if parallel.is_rank_zero():
# Loops that call handles.put
pass
parallel.barrier()
After this change, the code will still work in serial, even if mpi4py is not
installed.
To run this, where the above script is saved as main_bpod.py, execute:
mpiexec -n 8 python main_bpod.py
It is rare to need to handle parallelization yourself, but if you do,
you should use the provided mr.parallel_default_instance instance
as above.
Also provided are member functions parallel.get_rank() and
parallel.get_num_procs() (see parallel for details).
If you’re curious, the text files are saved in a format defined in
util.load_array_text() and util.save_array_text().
Example 4 – Inner product function¶
You are free to use any inner product function, as long as it has the interface
value = inner_product(vec1, vec2) and satisfies the mathematical
definition of an inner product (see Interfacing with your data).
This example uses the trapezoidal rule for inner products on an arbitrary
n-dimensional cartesian grid (see vectors.InnerProductTrapz).
The object weighted_IP is callable (it has a special method __call__) so
it acts as the inner product the usual way: value = weighted_IP(vec1, vec2).
import os
import numpy as np
from modred import parallel
import modred as mr
# Create directory for output files
out_dir = 'tutorial_ex4_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Define non-uniform grid and corresponding inner product weights
nx = 80
ny = 100
x_grid = 1. - np.cos(np.linspace(0, np.pi, nx))
y_grid = np.linspace(0, 1., ny) ** 2
Y, X = np.meshgrid(y_grid, x_grid)
# Create random snapshot data
num_vecs = 100
snapshots = [
mr.VecHandlePickle('%s/vec%d.pkl' % (out_dir, i))
for i in mr.range(num_vecs)]
if parallel.is_rank_zero():
for i, snap in enumerate(snapshots):
snap.put(np.sin(X * i) + np.cos(Y * i))
parallel.barrier()
# Calculate DMD modes and save them to pickle files
weighted_IP = mr.InnerProductTrapz(x_grid, y_grid)
my_DMD = mr.DMDHandles(inner_product=weighted_IP)
my_DMD.compute_decomp(snapshots)
my_DMD.put_decomp(
'%s/eigvals.txt' % out_dir, '%s/R_low_order_eigvecs.txt' % out_dir,
'%s/L_low_order_eigvecs.txt' % out_dir,
'%s/correlation_array_eigvals.txt' % out_dir,
'%s/correlation_array_eigvecs.txt' % out_dir)
mode_indices = [1, 4, 5, 0, 10]
modes = [
mr.VecHandlePickle('%s/mode%d.pkl' % (out_dir, i)) for i in mode_indices]
my_DMD.compute_exact_modes(mode_indices, modes)
Also shown in this example is the useful put_decomp, which, by default
saves the arrays associated with the decomposition to text files.
(See Array input and output.)
Again, this code can be executed in parallel without any modifications.
Example 5 – Shifting and scaling vectors using vector handles¶
Often vectors contain an offset (also called a shift or translation) such as a mean or equilibrium state, and one might want to do model reduction with this known offset removed. We call this offset the base vector, and it can be subtracted off by the vector handle class as shown in this example.
Note that handle.put does not use the base vector; the base vector is only
subtracted by handle.get.
You might also want to scale all of your vectors by factors as you retrieve them
for use in modred, and this can also be done by the handle.get function.
When using both base vector shifting and scaling, the default order is first
shifting then scaling: (vec - base_vec)*scale.
This examples uses quadrature weights, where each vector is weighted.
It also shows how to load vectors in one format (pickle, via
mr.VecHandlePickle) and save modes in another (text, via
mr.VecHandleArrayText).
import os
import numpy as np
from modred import parallel
import modred as mr
# Create directory for output files
out_dir = 'tutorial_ex5_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Create artificial sample times used as quadrature weights in POD
num_vecs = 100
quad_weights = np.logspace(1., 3., num=num_vecs)
base_vec_handle = mr.VecHandlePickle('%s/base_vec.pkl' % out_dir)
snapshots = [
mr.VecHandlePickle(
'%s/vec%d.pkl' % (out_dir, i),base_vec_handle=base_vec_handle,
scale=quad_weights[i])
for i in mr.range(num_vecs)]
# Save arbitrary snapshot data
num_elements = 2000
if parallel.is_rank_zero():
for snap in snapshots + [base_vec_handle]:
snap.put(np.random.random(num_elements))
parallel.barrier()
# Compute and save POD modes
my_POD = mr.PODHandles(inner_product=np.vdot)
my_POD.compute_decomp(snapshots)
my_POD.put_decomp('%s/sing_vals.txt' % out_dir, '%s/sing_vecs.txt' % out_dir)
my_POD.put_correlation_array('%s/correlation_array.txt' % out_dir)
mode_indices = [1, 4, 5, 0, 10]
modes = [
mr.VecHandleArrayText('%s/mode%d.txt' % (out_dir, i)) for i in mode_indices]
my_POD.compute_modes(mode_indices, modes)
# Check that modes are orthonormal
vec_space = mr.VectorSpaceHandles(inner_product=np.vdot)
IP_array = vec_space.compute_symm_inner_product_array(modes)
if not np.allclose(IP_array, np.eye(len(mode_indices))):
print('Warning: modes are not orthonormal')
print(IP_array)
At the end of this example, we use an instance of the low-level class
vectorspace.VectorSpaceHandles to check that the POD modes are
orthonormal.
It’s generally not necessary to use this class (or do this check), but if the
need arises, it should be used (instead of writing new code) since it is tested
and parallelized.
Example 6 – User-defined vectors and handles¶
So far, all of the vectors have been arrays, but you may want to apply modred to data saved in your own custom format with more complicated inner products and other operations. This is no problem at all; modred works with data in any format! That’s worth saying again: modred works with data in any format! Of course, you’ll have to tell modred how to interact with your data, but that’s pretty easy. You just need to define and use your own vector handle and vector objects.
There are two important new features of this example: a custom vector class
CustomVector and a custom vector handle class CustomVecHandle.
These definitions may be collected together in a file, for instance called
customvector.py:
import pickle
from copy import deepcopy
import numpy as np
import modred as mr
class CustomVector(mr.Vector):
def __init__(self, grids, data_array):
self.grids = grids
self.data_array = data_array
self.weighted_ip = mr.InnerProductTrapz(*self.grids)
def __add__(self, other):
"""Return a new object that is the sum of self and other"""
sum_vec = deepcopy(self)
sum_vec.data_array = self.data_array + other.data_array
return sum_vec
def __mul__(self, scalar):
"""Return a new object that is ``self * scalar`` """
mult_vec = deepcopy(self)
mult_vec.data_array = mult_vec.data_array * scalar
return mult_vec
def inner_product(self, other):
return self.weighted_ip(self.data_array, other.data_array)
class CustomVecHandle(mr.VecHandle):
def __init__(self, vec_path, base_handle=None, scale=None):
mr.VecHandle.__init__(self, base_handle, scale)
self.vec_path = vec_path
def _get(self):
file_id = open(self.vec_path, 'rb')
grids = pickle.load(file_id)
data_array = pickle.load(file_id)
file_id.close()
return CustomVector(grids, data_array)
def _put(self, vec):
file_id = open(self.vec_path, 'wb')
pickle.dump(vec.grids, file_id)
pickle.dump(vec.data_array, file_id)
file_id.close()
def inner_product(v1, v2):
return v1.inner_product(v2)
Instances of CustomVector meet the requirements for a vector object: vector
addition __add__ and scalar multiplication __mul__ are defined, and the
objects are compatible with an inner product function such as
inner_product(v1, v2).
Note that CustomVector inherits from a base class mr.Vector.
This is not required, but is recommended, as the base class provides some useful
additional methods.
The member function inner_product is useful, but not required.
This example also uses the trapezoidal rule for inner products to account for a
3D arbitrary cartesian grid (vectors.InnerProductTrapz).
The class CustomVecHandle inherits from a base class mr.VecHandle, and
defines methods _get and _put, which load and save vectors from/to
Pickle files.
Note the leading underscore: the functions get and put (without leading
underscore) are defined in the VecHandle base class, and take care of
scaling or subtracting a base vector.
The methods _get and _put defined here are in turn called by the base
class (the “template method” design pattern).
While you don’t need to understand the guts of these base classes, more is
covered in Interfacing with your data.
Here’s an example using these classes:
import os
import numpy as np
from modred import parallel
import modred as mr
from customvector import CustomVector, CustomVecHandle, inner_product
# Create directory for output files
out_dir = 'tutorial_ex6_out'
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
# Define snapshot handles
direct_snapshots = [
CustomVecHandle('%s/direct_snap%d.pkl' % (out_dir, i), scale=np.pi)
for i in mr.range(10)]
adjoint_snapshots = [
CustomVecHandle('%s/adjoint_snap%d.pkl' % (out_dir, i), scale=np.pi)
for i in mr.range(10)]
# Create random snapshot data
nx = 50
ny = 30
nz = 20
x = np.linspace(0, 1, nx)
y = np.logspace(1, 2, ny)
z = np.linspace(0, 1, nz) ** 2
if parallel.is_rank_zero():
for snap in direct_snapshots + adjoint_snapshots:
snap.put(CustomVector([x, y, z], np.random.random((nx, ny, nz))))
parallel.barrier()
# Compute and save balanced POD modes
my_BPOD = mr.BPODHandles(inner_product=inner_product)
my_BPOD.sanity_check(direct_snapshots[0])
sing_vals, L_sing_vecs, R_sing_vecs = my_BPOD.compute_decomp(
direct_snapshots, adjoint_snapshots)
# Choose modes so that BPOD projection has less than 10% error
sing_vals_norm = sing_vals / np.sum(sing_vals)
num_modes = np.nonzero(np.cumsum(sing_vals_norm) > 0.9)[0][0] + 1
mode_nums = list(mr.range(num_modes))
direct_modes = [
CustomVecHandle('%s/direct_mode%d.pkl' % (out_dir, i)) for i in mode_nums]
adjoint_modes = [
CustomVecHandle('%s/adjoint_mode%d.pkl' % (out_dir, i)) for i in mode_nums]
my_BPOD.compute_direct_modes(mode_nums, direct_modes)
my_BPOD.compute_adjoint_modes(mode_nums, adjoint_modes)
This example is similar to previous ones, but some aspects are worth pointing
out.
The call to my_BPOD.sanity_check() runs some basic tests to verify that the
vector handles and vectors behave as expected, so this can be useful for
debugging.
After execution, the modes are saved to direct_mode0.pkl,
direct_mode1.pkl … and adjoint_mode0.pkl, adjoint_mode1.pkl.
Also, note that the only time the CustomVector class is used is in
generating the “fake” random data: most scripts will only need to deal with the
vector handle classes, not the vectors themselves.
When you’re ready to start using modred, take a look at what types of vectors,
file formats, and inner products are supplied in vectors.
If you don’t find what you need, you can define your own vectors and vector
handles following examples like this.
Built-in classes like VecHandleArrayText and VecHandlePickle are common
cases and serve as good examples since your own custom vector handle classes
will probably resemble them.
As usual, this example can be executed in parallel without any modifications.
Array input and output¶
By default, put_array and get_array save and load to text files.
If you prefer a different format, you can pass your own functions as keyword
arguments put_array and get_array to the constructors.
The functions should have the following interfaces:
put_array(array, array_dest)
and array = get_array(array_source).
The array argument could be a 1D or 2D array.
References¶
| [HLBR] | (1, 2, 3) P. Holmes, J. L. Lumley, G. Berkooz, and C. W. Rowley. Turbulence, Coherent Structures, Dynamical Systems and Symmetry, 2nd edition, Cambridge University Press, 2012. |
| [TRLBK] | J. H. Tu, C. W. Rowle, D. M. Luchtenburg, S. L. Brunton, J. N. Kutz. On Dynamic Mode Decmposition: Theory and Applications. Journal of Computational Dynamics, 1:391-421, Dec. 2014. |