VectorSpace¶
-
class
modred.vectorspace.VectorSpaceArrays(weights=None)[source]¶ Implements inner products and linear combinations using data stored in arrays.
- Kwargs:
inner_product_weights: 1D array of inner product weights. Corresponds to in inner product
in inner product 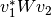 .
.
-
class
modred.vectorspace.VectorSpaceHandles(inner_product=None, max_vecs_per_node=None, verbosity=1, print_interval=10)[source]¶ Provides efficient, parallel implementations of vector space operations, using handles.
- Kwargs:
inner_product: Function that computes inner product of two vector objects.max_vecs_per_node: Maximum number of vectors that can be stored in memory, per node.verbosity: 1 prints progress and warnings, 0 prints almost nothing.print_interval: Minimum time (in seconds) between printed progress messages.
This class implements low-level functions for computing large numbers of vector sums and inner products. These functions are used by high-level classes in
pod,bpod,dmdandltigalerkinproj.Note: Computations are often sped up by using all available processors, even if this lowers
max_vecs_per_nodeproportionally. However, this depends on the computer and the nature of the functions supplied, and sometimes loading from file is slower with more processors.-
compute_inner_product_array(row_vec_handles, col_vec_handles)[source]¶ Computes array whose elements are inner products of the vector objects in
row_vec_handlesandcol_vec_handles.- Args:
row_vec_handles: List of handles for vector objects corresponding to rows of the inner product array. For example, in BPOD this is the adjoint snapshot array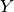 .
.col_vec_handles: List of handles for vector objects corresponding to columns of the inner product array. For example, in BPOD this is the direct snapshot array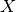 .
.- Returns:
IP_array: 2D array of inner products.
The vectors are retrieved in memory-efficient chunks and are not all in memory at once. The row vectors and column vectors are assumed to be different. When they are the same, use
compute_symm_inner_product()for a 2x speedup.Each MPI worker (processor) is responsible for retrieving a subset of the rows and columns. The processors then send/receive columns via MPI so they can be used to compute all inner products for the rows on each MPI worker. This is repeated until all MPI workers are done with all of their row chunks. If there are 2 processors:
| x o | rank0 | x o | | x o | - | o x | rank1 | o x | | o x |
In the next step, rank 0 sends column 0 to rank 1 and rank 1 sends column 1 to rank 0. The remaining inner products are filled in:
| x x | rank0 | x x | | x x | - | x x | rank1 | x x | | x x |
When the number of columns and rows is not divisible by the number of processors, the processors are assigned unequal numbers of tasks. However, all processors are always part of the passing cycle.
The scaling is:
- num gets / processor ~

- num MPI sends / processor ~

- num inner products / processor ~

where
 is number of rows,
is number of rows, 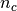 number of columns,
number of columns,
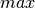 is
is
max_vecs_per_proc = max_vecs_per_node/num_procs_per_node, and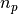 is the number of MPI workers (processors).
is the number of MPI workers (processors).If there are more rows than columns, then an internal transpose and un-transpose is performed to improve efficiency (since
only
appears in the scaling in the quadratic term).
-
compute_symm_inner_product_array(vec_handles)[source]¶ Computes symmetric array whose elements are inner products of the vector objects in
vec_handleswith each other.- Args:
vec_handles: List of handles for vector objects corresponding to both rows and columns. For example, in POD this is the snapshot array.- Returns:
IP_array: 2D array of inner products.
See the documentation for
compute_inner_product_array()for an idea how this works. Efficiency is achieved by only computing the upper-triangular elements, since the array is symmetric. Within the upper-triangular portion, there are rectangular chunks and triangular chunks. The rectangular chunks are divided up among MPI workers (processors) as weighted tasks. Once those have been computed, the triangular chunks are dealt with.
-
lin_combine(sum_vec_handles, basis_vec_handles, coeff_array, coeff_array_col_indices=None)[source]¶ Computes linear combination(s) of basis vector objects and calls
puton result(s), using handles.- Args:
sum_vec_handles: List of handles for the sum vector objects.basis_vec_handles: List of handles for the basis vector objects.coeff_array: Array whose rows correspond to basis vectors and whose columns correspond to sum vectors. The rows and columns correspond, by index, to the listsbasis_vec_handlesandsum_vec_handles. In matrix notation, we can writesums = basis * coeff_array- Kwargs:
coeff_array_col_indices: List of column indices. Only thesum_vecscorresponding to these columns of the coefficient array are computed. If no column indices are specified, then all columns will be used.
Each MPI worker (processor) retrieves a subset of the basis vectors to compute as many outputs as an MPI worker (processor) can have in memory at once. Each MPI worker (processor) computes the “layers” from the basis it is responsible for, and for as many modes as it can fit in memory. The layers from all MPI workers (processors) are summed together to form the
sum_vecsandputis called on each.Scaling is:
num gets/worker =

passes/worker =

scalar multiplies/worker =

where
 is number of sum vecs,
is number of sum vecs,  is
number of basis vecs,
is number of processors,
=
is
number of basis vecs,
is number of processors,
= max_vecs_per_node.
-
print_msg(msg, output_channel='stdout')[source]¶ Print a message from rank zero MPI worker/processor.
-
sanity_check(test_vec_handle)[source]¶ Checks that user-supplied vector handle and vector satisfy requirements.
- Args:
test_vec_handle: A vector handle to test.
The add and multiply functions are tested for the vector object. This is not a complete testing, but catches some common mistakes. An error is raised if a check fails.